Research

Hi I'm Vivek Jayaram, a machine learning researcher at University of Washington. My research interests lie at the intersection of machine learning, audio, music, and vision. Some of the conferences I've published at include CVPR, NeurIPS, and ICML.

Constrained Diffusion Implicit Models
Vivek Jayaram, Ira Kemelmacher-Shlizerman, Steven M. Seitz, John ThickstunNeurips 2025
We show a way to sample from diffusion models using constraints. Our method is also extremely fast compared to others. This is useful for tasks like inpainting, super-resolution, and colorization
HRTF Estimation in the Wild
Vivek Jayaram, Ira Kemelmacher-Shlizerman, Steven M. SeitzUIST 2024
We built a way to measure your personalized Head Related Transfer Function (HRTF) using everyday earbuds. HRTF plays an important part in providing realistic audio experiences when using headphones or in VR/AR applications.
ClearBuds: Wireless Binaural Earbuds for Speech Enhancement
Ishan Chatterjee* Maruchi Kim* Vivek Jayaram* Shyamnath Gollakota, Ira Kemelmacher-Shlizerman, Shwetak Patel, Steven M. SeitzMobisys 2022 (Best Demo Runner Up)
We built our own earbuds that isolte your voice on phone calls. They use one microphone in each ear, which are time-synced, and use that to perform better than airpods or existing software like Zoom
Parallel and Flexible sampling from Auto-regressive Models
Vivek Jayaram*, John Thickstun*ICML 2021
In this paper we turn auto-regressive models like WaveNet into diffusion style models. By sampling from them based on the gradients of the distribution, we can perform conditional tasks like source separation, inpainting, and super-resolution with pretrained WaveNet models.
The Cone of Silence: Speech Separation by Localization
Teerapat Jenrungrot*, Vivek Jayaram*, Steve Seitz, Ira Kemelmacher-ShlizermanNeurips 2020 (Oral)
We present a new approach to speech separation and localization. The method uses a spatial binary search and can handle arbitrary many speakers, moving speakers, and background sounds.
Source Separation with Deep Generative Priors
Vivek Jayaram*, John Thickstun*ICML 2020
Generative modeling has gotten so good at producing unconditional samples, but other tasks like source separation don't produce equally convincing results. In this paper we propse a new way to tap into state-of-the art generative models to solve source separation. We call our method BASIS Separation (Bayesian Annealed SIgnal Source Separation).
Background Matting: The World is Your Green Screen
Soumyadip Sengupta, Vivek Jayaram, Brian Curless, Steve Seitz, Ira Kemelmacher-ShlizermanCVPR 2020
Background replacement has many applications from VFX to privacy (anyone tried to use zoom's virtual background??). In this work we push the state of the art for separating a subject from their background.
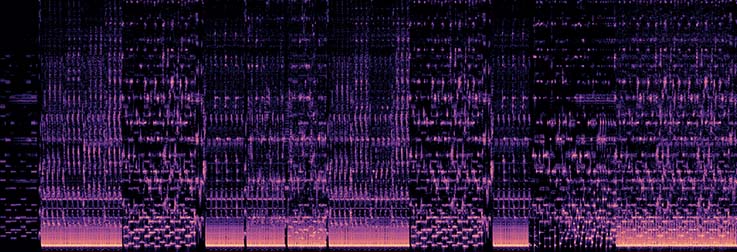
Pychorus: Finding Choruses in Songs with Python
Vivek JayaramTowards Data Science
Do you ever feel like songs nowadays repeat themselves a lot? This was the motivation for a recent method I worked on for detecting choruses in music. By looking for repetition in the spectrogram it's possible to discover song structure. The method is fast, runs on the cpu, and can be installed with pip. It works on a wide variety of music genres as well.

Multiplicative Feature-Based Attention for Transfer Learning in CNNs
Vivek JayaramUndergraduate Thesis
During my senior year I was a researcher in the Cox Lab at Harvard at the intersection of neuroscience and computer vision. My thesis project borrowed the idea of Feature Based Attention from neuroscience to improve visual classification in neural networks.